How to Estimate Entropy Wrong
Table of Contents
One common attempt to estimate entropy from samples is via discretisation and counting. However, it can easily go wrong.
The approach
This particular approach I refer to for entropy estimation consists three steps:
- Discretise data into
 bins
bins - Count data and normalise the counts into probabilities

- Estimate the entropy as

Intuitively, we may also believe with more data and a large , we can get a good estimate.
Experiments and oops
This method sounds reasonable and it’s worth to check how it performs on simulated Gaussian random variables,
for which we know the ground truth entropy.
For this I simulated  samples from Gaussians with
samples from Gaussians with  mean and standard deviation
mean and standard deviation ![$\sigma \in [0.1, 1, 5, 10, 15, 20]$](.cache/org-latex/estimate-entropy-wrong_290d23e0eb5610c5eb59095fc33da950c3ec7b37.svg) .
For binning, I uniformly discretise the data into
.
For binning, I uniformly discretise the data into  bins.
Figure 1 shows the estimated entropy as well as the ground truth,
computed as
bins.
Figure 1 shows the estimated entropy as well as the ground truth,
computed as  .
.
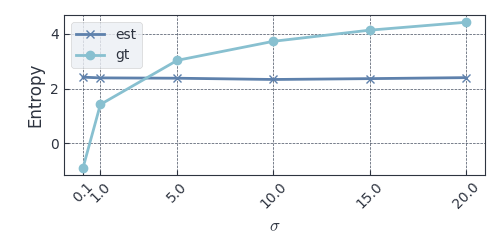
Figure 1: Estimated (est) and ground truth (gt) entropy for Gaussians with  varying
varying
Looks not only the estimates differ from the ground truth a lot (except somewhere between  and
and  which is close) but also stays almost constant with varying , which is a bit unexpected.
Would it be because the number of bins we set is just too bad?
To check this,
I perform the same experiments but now with
which is close) but also stays almost constant with varying , which is a bit unexpected.
Would it be because the number of bins we set is just too bad?
To check this,
I perform the same experiments but now with  fixed and the number of bins varying
fixed and the number of bins varying ![$N \in [10, 20, 30, 40]$](.cache/org-latex/estimate-entropy-wrong_c91077304a829f9993100ee525cf6a6e3b5c6ba9.svg) ; figure 2 shows the results.
; figure 2 shows the results.
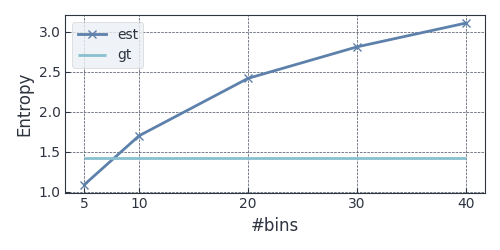
Figure 2: Estimated (est) and ground truth (gt) entropy for Gaussians with varying
So it looks like for this particular , there is only one binning size that gives close estimate.
This doesn’t help the situation and is away from our intuition of increasing may give a better estimate.
To make sure this is not a special case for this particular ,
I check the effect of and in a single picture by varying both and the number of bins, which given the contour plot in figure 4.
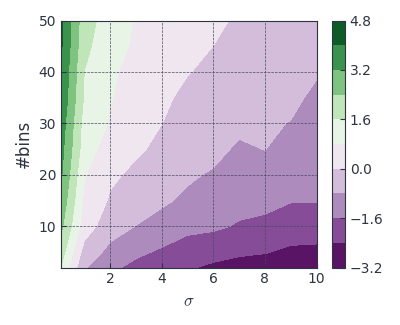
Figure 3: Difference between estimated (est) and ground truth (gt) entropy for Gaussians with and the number of bins varying
Looks like there is some particular number of bins (see the boundary for difference equal to in colo bar) required for a different unlike one might hope we can simply improve the estimate by using more bins.
This almost makes this estimate useless because there is no easy way to tune it without knowing the ground truth.
What’s wrong and is there something we can do to have it fixed?
What’s going on here?
To understand what’s going on here, we need to review some basic concepts.
Entropy and differential entropy
The entropy (or discrete entropy or Shannon entropy) itself is only defined for discrete probability distributions.
For a discrete distribution with support  of the random variable
of the random variable  ,
the entropy
,
the entropy  is defined as
is defined as

where  .
.
For continuous distributions,
the correspondence is differential entropy,
suggested by Claude Shannon without a formal justification11 By this I mean, to extend the idea of entropy, Shannon simply made an analogue of the discrete entropy instead of deriving it, according to the Wikipedia page..
For a continuous distribution with probability density function  and support
and support  ,
the differential entropy is defined as
,
the differential entropy is defined as

What entropy are we estimating?
The first thing to note here is that (by using “the approach” in the beginning) we are attempting to approximating the differential entropy (for the target continuous random variable) via entropy (for the discretised version). The first question to ask is: Is this idea/goal correct?
Approximating the differential entropy
Although intuitively one might think if we have an infinite number of data points and keep increasing the number of bins, we can approximate the target differential entropy pretty well, this is actually not true.
To see the connection between differential entropy and (discrete) entropy,
we start with the following equivalence for any continuous function discretised into bins of size 
 1
1
where  ,
following the mean-value theorem22 No panic—the mean-value theorem basically says these
,
following the mean-value theorem22 No panic—the mean-value theorem basically says these  exisit..
exisit..
Then using the relationship between bin proportion  , bin size and density ,
, bin size and density ,  , we can write down the Shannon entropy of the discretised density
, we can write down the Shannon entropy of the discretised density 

where the second equality is simply based on the property of logorithm33 That is  ..
..
Taking the limit  ,
using the property in equation 3
we have
,
using the property in equation 3
we have

This is actually a known fact that the differential entropy is not a limit of the Shannon entropy and there is in fact an infinite offset/bias in the limit!44 Besides, the differential entropy also lacks a number of properties that Shannon entropy has such as positivity or invariant to change of variables.
Importantly for us, this explain why we saw a monotonically increasing line in figure 2—we are simply pushing  with a decreasing !
with a decreasing !
The fix
The clear fix is to use the following equality we have established so far:

together with the relation , which gives:

where  is the bin size for bin
is the bin size for bin  .
.
In fact, what we just derived is referred as the histogram estimator of entropy in the literature.
Experiments with the fix
Let’s repeat the last experiment with this fix! The results is given in Figure 4.
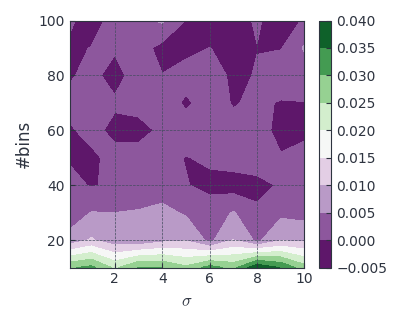
Figure 4: Difference between estimated (est) and ground truth (gt) entropy for Gaussians with and the number of bins varying (fixed)
Great! Now with a reasonable large number of bins ( ) our estimator work pretty nice!
Below is the same experiment but did for Gamma and Beta with varying one of their parameters (I only do this because it’s a single input change to my script which uses Distributions.jl🙂):
) our estimator work pretty nice!
Below is the same experiment but did for Gamma and Beta with varying one of their parameters (I only do this because it’s a single input change to my script which uses Distributions.jl🙂):
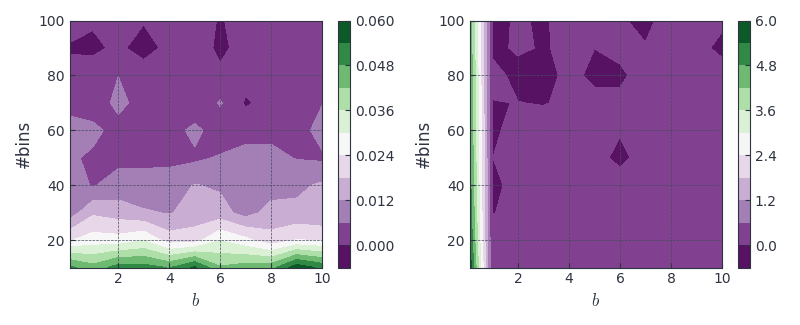
Figure 5: Difference between estimated (est) and ground truth (gt) entropy for Gamma( ) (left) and Beta() with
) (left) and Beta() with  and the number of bins varying (fixed)
and the number of bins varying (fixed)
Looks like the estimator still works pretty well except from some very skewed case like Beta( ) (left most of the right plot).
) (left most of the right plot).
🎉
Some extra stuff
Limiting density of discrete points
On the other side, the actual limit of the (Shannon) entropy is referred as the limiting density of discrete points (LDDP), suggested by [Jaynes, 1957], which is defined as

where  is the density of a uniform distribution over the support of .
This actually looks interesting because it’s in fact the Kullback–Leibler divergence between and !
is the density of a uniform distribution over the support of .
This actually looks interesting because it’s in fact the Kullback–Leibler divergence between and !
For a 1D case where the domain is  , we simply have
, we simply have  .
With some moving-around and using
.
With some moving-around and using  55 Simply because is a probability density and it’s true for any density function and constant
55 Simply because is a probability density and it’s true for any density function and constant  that
that  ., we have
., we have

where  is actually the bin size with uniform binning!
is actually the bin size with uniform binning!
Importantly, this also reveals a fact to us: What we estimate is the entropy of truncated Gaussian where the truncation is done as the min and max of the samples—as we have no way to distinguish if it’s really truncated or not beyond this!
Related mistake
Another mistake could arise from estimating the mutual information based on the same strategy. Moreover the mutual information between discrete variables also has different properties than that of continuous variables—see their wiki pages for more information.
References
| [Jaynes, 1957] | Jaynes, E. T. (1957). Information theory and statistical mechanics. Physical review, 106(4):620. |
Footnotes
By this I mean, to extend the idea of entropy, Shannon simply made an analogue of the discrete entropy instead of deriving it, according to the Wikipedia page.
No panic—the mean-value theorem basically says these exisit.
That is .
Besides, the differential entropy also lacks a number of properties that Shannon entropy has such as positivity or invariant to change of variables.
Simply because is a probability density and it’s true for any density function and constant that .