A Short Note on Stratified Sampling
Table of Contents
Stratified sampling is a Monte Carlo (MC) method to estimate an integral that consist a distribution  and a function of interest
and a function of interest 
 1
1
via partitioning  into smaller groups, called strata.
It is a type of quasi-Monte Carlo (QMC) method as it introduces deterministic procedures into the MC estimation.
Same as crude Monte Carlo the estimation is still unbiased;
however, the variance of the estimator can be smaller than crude MC.
into smaller groups, called strata.
It is a type of quasi-Monte Carlo (QMC) method as it introduces deterministic procedures into the MC estimation.
Same as crude Monte Carlo the estimation is still unbiased;
however, the variance of the estimator can be smaller than crude MC.
(Crude) Monte Carlo
The (crude) Monte Carlo estimator of  is
is

where  and
and  is the number of MC samples.
is the number of MC samples.
This estimator is an unbiased1 estimator of the original target :
![\begin{equation*}
\begin{aligned}
\E[\hat{I}]
&= \E \left[\frac{1}{N} \sum_{i=1}^N f(x^i) \right] \\
&= \frac{1}{N} \sum_{i=1}^N \E [f(x^i)] \\
&= \frac{1}{N} \sum_{i=1}^N I \\
&= I
\end{aligned}.
\end{equation*}](.cache/org-latex/stratified-sampling_2cd066f4f329b48ed66652f6aeab771102ec4460.svg)
Now let’s look at the variance of the estimator ![$\Var[\hat{I}]$](.cache/org-latex/stratified-sampling_0dd743d04e5ecd92f623fae38f60ee9b57c6a4ce.svg) .
We first need to define
.
We first need to define  , which is the variance of
, which is the variance of  under the distribution
under the distribution  . Now the variance of interest is
. Now the variance of interest is
![\begin{equation*}
\begin{aligned}
\Var[\hat{I}]
&= \Var \left[\frac{1}{N} \sum_{i=1}^N f(x^i) \right] \\
&= \frac{1}{N^2} \sum_{i=1}^N \Var[f(x^i)] \\
&= \frac{1}{N^2} \sum_{i=1}^N \sigma^2 \\
&= \frac{\sigma^2}{N} \\
\end{aligned}.
\end{equation*}](.cache/org-latex/stratified-sampling_2f49749cba0311645a3c35afe1bcd9c0a0c15268.svg)
As it can be seen, the variance drops with the order of  by using more samples.
by using more samples.
Example
I now use an area estimation example2 to demonstrate how the empirical estimate of the variance of the crude Monte Carlo estimator changes as the number of samples increases.
The area  I am interested in estimating is illustrated in the figure below.
I am interested in estimating is illustrated in the figure below.
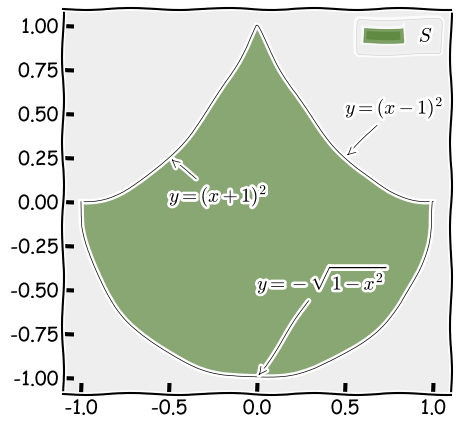
Figure 1: The area
This is equivalent to computing the integral below
![\begin{equation*}
\begin{aligned}
S
&= \int_{[-1, 1]^2} \1(x \in S) dx \\
&= 4 \int_{[-1, 1]^2} \frac{1}{4} \1(x \in S) dx \\
&= 4 \int_{[-1, 1]^2} \uniform(x; [-1, 1]^2) \1(x \in S) dx
\end{aligned}
\end{equation*}](.cache/org-latex/stratified-sampling_88ee61def6533ae7afad90a8c0b917d7b8c6ceb1.svg)
where  is the indicator function and
is the indicator function and  is the uniform distribution over
is the uniform distribution over  .
.
The crude MC estimator for is then

where ![$x^i \sim \uniform(x; [-1, 1]^2)$](.cache/org-latex/stratified-sampling_1496e8395b2b7756c5d53181ba3efb9ef48e2d10.svg) and is the MC samples.
and is the MC samples.
I now visualise how the variance of  changes as increases.
changes as increases.
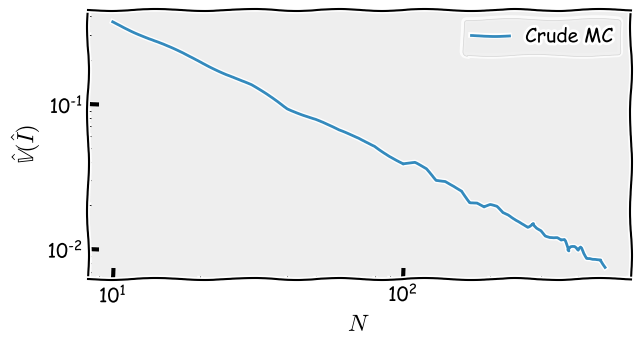
Figure 2: Variance convergence of crude MC
Note that both the x- and y-axis are in logarithm scale.
As we can see, it matches our analysis results, which is .3
Stratified sampling
Now, we look at how stratified sampling works and
how the variance of the corresponding estimator changes depending on different stratifications.
For the sake of simplicity, we consider the case where ![$p(x) = \uniform([0, 1]^D)$](.cache/org-latex/stratified-sampling_00719969583bb7b5a8ae9652fef2ca7ddce86389.svg) a
a ![\[D\]](.cache/org-latex/stratified-sampling_5ff7ca7f3c2cee415a76e2883e2acc6b45ec0cc3.svg) -dimensional uniform distribution for the integral in equation 1.4
We first partition into
-dimensional uniform distribution for the integral in equation 1.4
We first partition into  strata s.t.
strata s.t.  .
Then, as the simplest way of performing stratified sampling,
we uniformly draw independent Monte Carlo samples for each stratum
.
Then, as the simplest way of performing stratified sampling,
we uniformly draw independent Monte Carlo samples for each stratum  ,
and the overall estimator is given as below
,
and the overall estimator is given as below

where  are samples that lie in and
are samples that lie in and  is the number of MC samples in stratum
is the number of MC samples in stratum  .
.
The mean of within each stratum is

and the corresponding variance is

As it is mentioned in the beginning,  is still an unbiased estimator of .
We can validate this by computing the mean of
is still an unbiased estimator of .
We can validate this by computing the mean of
![\begin{equation*}
\begin{aligned}
\E[\hat{I}_\text{strat}]
&= \E\left[\sum_{h=1}^H \frac{|\sX_h|}{n_h}\sum_{i=1}^{n_h} f(x_h^i)\right] \\
&= \sum_{h=1}^H \frac{|\sX_h|}{n_h}\sum_{i=1}^{n_h} \E[f(x_h^i)] \\
&= \sum_{h=1}^H \frac{|\sX_h|}{n_h}\sum_{i=1}^{n_h} |\sX_h|^{-1} \int_{\sX_h} f(x) \deriv x \\
&= \sum_{h=1}^H \frac{1}{n_h}\sum_{i=1}^{n_h} \int_{\sX_h} f(x) \deriv x \\
&= \sum_{h=1}^H \int_{\sX_h} f(x) \deriv x \\
&= \int_{\sX_1 \cup \dots \cup \sX_H} f(x) \deriv x \\
&= \int_\sX f(x) \deriv x \\
&= I
\end{aligned}.
\end{equation*}](.cache/org-latex/stratified-sampling_b11342fca7e6e85d4d4ae3a3580e1663b0c412bc.svg)
The variance of is then
![\begin{equation*}
\begin{aligned}
\Var[\hat{I}_\text{strat}]
&=\Var\left[\sum_{h=1}^H \frac{|\sX_h|}{n_h}\sum_{i=1}^{n_h} f(x_h^i)\right] \\
&=\sum_{h=1}^H \Var\left[\frac{|\sX_h|}{n_h}\sum_{i=1}^{n_h} f(x_h^i)\right] \\
&=\sum_{h=1}^H \frac{|\sX_h|^2}{n_h^2}\Var\left[\sum_{i=1}^{n_h} f(x_h^i)\right] \\
&=\sum_{h=1}^H \frac{|\sX_h|^2}{n_h^2}\sum_{i=1}^{n_h} \Var[f(x_h^i)] \\
&=\sum_{h=1}^H \frac{|\sX_h|^2}{n_h^2}\sum_{i=1}^{n_h} \sigma_h^2 \\
&=\sum_{h=1}^H \frac{|\calX_h|^2}{n_h}\sigma_h^2
\end{aligned}.
\end{equation*}](.cache/org-latex/stratified-sampling_27103c321d5d22cd088314a43c0c5724bca18fcc.svg)
Effect of different allocation strategies
We are interested in comparing this estimator against (crude) Monte Carlo.
In particular,
we’d like to show that when is allocated proportionally to  the estimator can only decrease in variance as compared to (crude) Monte Carlo.
the estimator can only decrease in variance as compared to (crude) Monte Carlo.
In order to show this,
we need to rewrite the variance of crude Monte Carlo in terms of strata.
Let’s introduce  - the stratum that contains
- the stratum that contains  :
:  .
By the law of total variance, we have
.
By the law of total variance, we have
![\begin{equation*}
\begin{aligned}
\sigma^2 = \Var[f(x)]
&= \E[\Var[f(x) \given h(x)]] + \V[\E[f(x) \given h(x)]] \\
&= \sum_{h=1}^H |\sX_h| \sigma_h^2 + \sum_{h=1}^H |\sX_h| (\mu_h - I)^2
\end{aligned}.
\end{equation*}](.cache/org-latex/stratified-sampling_6dfb867fde16c06b4e152d6f56a7c05b99f72128.svg)
Thus ![$\Var[\hat{I}] = \frac{\sigma^2}{n} = \frac{1}{n} \left( \sum_{h=1}^H |\sX_h| \sigma_h^2\right) + \frac{1}{n} \left(\sum_{h=1}^H |\sX_h| (\mu_h - I)^2 \right)$](.cache/org-latex/stratified-sampling_555b65a2e9dae3e57133a5469289e4f0beff4965.svg)
Note that in the case of proportional allocation,
because  ,
,
![\begin{equation*}
\Var[\hat{I}_\mathrm{STRAT}] = \frac{1}{n} \sum_{h=1}^H |\sX_h| \sigma_h^2
\end{equation*}](.cache/org-latex/stratified-sampling_30362aa6e81b6a39b4e0a9b21bd3400263f6f12b.svg)
which is smaller than .
Although it is not the optimal allocation5,
proportional allocation as applied to stratified sampling will never increase the variance over that of crude Monte Carlo.
Also, note that a poor allocation can also increase the variance of the estimator in comparison to crude Monte Carlo.
Effect of different stratification methods
It is interesting to note that, if is in 2D and is dominated by the horizontal direction more than the vertical direction,
partitioning in the horizontal direction would be more effective than partitioning in the vertical direction.
We will see it in the example soon.
Example (continued)
We continue with the example above by looking at 2 ways of stratifying the previously defined area.
- Vertically partitioning the space into 10 parts
- Horizontally partitioning the space into 10 parts
We illustrate where the samples are located for each method and for crude Monte Carlo in the figure below.
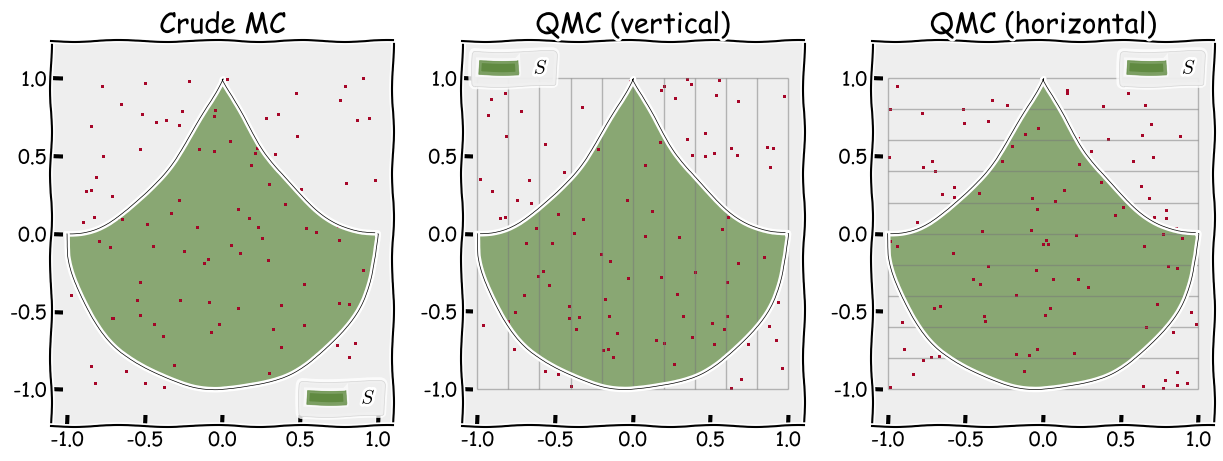
Figure 3: Different ways of sampling: crude MC (left), stratified sampling with vertical partitioning (middle) and stratified sampling with horizontal paritioning (right)
Notice that there are 100 samples in total for each method and that, for the stratified sampling methods, there are exactly 10 samples in each box.
Now what is interesting is the rate of variance of each estimator as the number of samples increase (shown below).
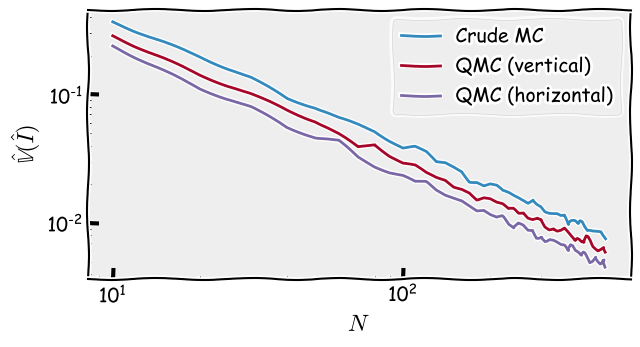
Figure 4: Variance convergence: crude MC v.s. quasi MC with different paritioning
As it can be seen, both QMC methods converge faster than crude Monte Carlo, as expected by our analysis. What’s more interesting is that horizontally partitioning the space is more effective than vertically partitioning it. This is because the pre-defined shape is dominated by the y-axis and not the x-axis. This domination can be explained by the shape’s symmetry along the y-axis and not the x-axis which means that the y-axis contains more information about the shape.
 is an unbiased estimator of
is an unbiased estimator of ![$\E[\hat{I}] = I$](.cache/org-latex/stratified-sampling_bc17c67873023c078341accc5613c8c7f4f7a951.svg) .
.
 .
.
 in a log-log plot is a straight line.
in a log-log plot is a straight line.
